清源团队大创项目,Java模糊测试优化,任务初期阅读论文:SemanticFuzzingWithZest
模糊测试
模糊测试首先需要大量的测试用例,即种子输入。
通过对已有的种子进行变异,得到大量的测试种子,然后通过对这些种子进行过滤,让这些测试种子变成“精品”,减少测试次数,更快发现漏洞。
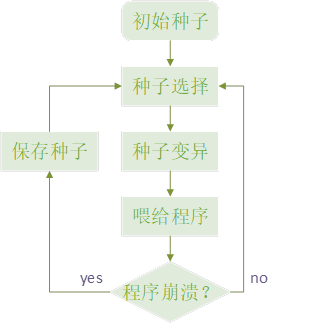
筛选的标准有很多可以选择,本文选择的是以测试样例的覆盖率为标准,感觉听起来和离散数学中的最大相容类,或者是线性代数中的极大线性无关组有点相似诶。
从网上能找到的比较流行的模糊测试工具是AFL,一个导向fuzzing工具,这个似乎之前是安装过的,不过不会用,当时就当是Linux系统练手用的,也没深究。下面稍稍记录一些普通知识,AFL以后有时间就另开一篇博客写吧。
Fuzzing一般分为两类,分别是:
- 盲模糊测试(blind fuzzing)
- 导向模糊测试(guided fuzzing)
**盲模糊测试(blind fuzzing)**倾向于生成大量数据,通过量来撞触发漏洞的概率。**导向模糊测试(guided fuzzing)**则是关注测试数据的质量,期望生成更加有效地测试数据去提升触发漏洞的概率。
结构化模糊测试(structured fuzzing)
通常,二进制模糊测试工具(例如AFL和libFuzzer)都会把输入以二进制形式进行操作。
但是如果被测试的程序需要高度结构化的输入(比如XML文档),那么在二进制水平上的种子变异通常会产生语法上的错误,这样不仅会影响效率,也会造成一些核心内容不容易被检测到。
结构化模糊测试工具会根据被测试程序所在领域的特定知识,去组织生成合乎语法要求的特定输入。GitHub上**JQF的说明文档**给出了一些利用libFuzzer进行测试的C++和Rust程序的例子。
基于发生器(generator-based)的模糊测试(QuickCheck)
目前有一些陈述式的结构化输入生成工具 context-free grammars or protocol buffers,JQF使用QuickCheck的命令式方法指定输入空间:任意生成器程序,其工作是生成单个随机输入。(这句话看不懂诶)。我们很容易去写一些生成器程序,但是我们很难去评估这个生成器中,生成的例子,在fuzzing中的具体效果。
语义模糊测试(Zest)
JQF支持Zest算法。Zest算法通过代码覆盖率、输入有效性这两个反馈来指导QuickCheck类型的生成器,让他们去生成结构化的数据去测试语义上更加深层的bug。JQF使用字节码工具(bytecode instrumentaiton)来获取代码覆盖率,使用JUnit的Assume提供的API去来获取输入的有效性,当所有的assume都被满足的时候,这份输入被认为是有效的。
Zest方法
Zest是一种算法,它在生成语义合法的过程中更加偏向于以覆盖率作为指导。最大化覆盖率是指,尽可能通过少量的数据去测试全部的程序分支,以期达到更加高效的成果。
Zest算法的目标是找出传统模糊测试工具找不到的,更深的语义bug。通常情况下,这些bug都是只强调错误处理逻辑(这一句没看懂…)
JQF框架
JQF是一个模块化的框架,支持一下可作为指南的模糊测试前端。其中包括使用Zest进行的语义模糊测试,也就是本篇论文所提到的那个工具。
一些词汇
| 词汇 | 释义 |
|---|---|
| parse | 进行语法分析 |
| syntactic | 语法的 |
| semantic | 语义的 |
| parametric | 参数的 |
| mutation | 变异 |
| bias | 偏向于 |
| leverage | 影响力,杠杆作用 |
| declarative | 陈述式的 |
| imperative | 命令式的 |